CH1: Web Application Fundamentals
This chapter introduces the Worldwide Web and outlines important concepts related to web applications. Before getting into Web Security, the learner must have a solid understanding of the Web, as outlined in this chapter.
Learning OutcomesLab Activity: Web Basics
In this practical activity, you will establish a basic understanding of how the Web works.
Coming Soon »The Worldwide WebThe Worldwide Web is a global cyberspace characterized by availability, ubiquity, and anonymity. Because of its “open” nature, the Web provides an endless repository of information in a number of formats. There are hundreds of thousands of websites out there and tens of millions of users surfing the Web. Some people love the Web because of the wealth of information it provides. Others hate it because of the time wasted on useless surfing. And many fear its dark and sinister side. Regardless of how we feel about the Web, it's here to stay. It's where we conduct business and shop anywhere and anytime. It's where we watch movies and read the news. It's where we connect and communicate across the globe. And it's where we research and study. Due to its popularity, the Web is both an object and a subject of security attacks.
As individuals surfing the Web, we are concerned about our privacy and even safety. As owners of websites, we are concerned about the confidentiality, integrity, and availability of our information resources. Therefore, online security is not an option but a critical requirement. One aspect of online security is securing web applications that represent the online presence of many organizations.
First things first...
Before we get into the security part of the course, we must understand what a web application is, how it's structured, and how it works.
Web TerminologyWebsite
A website is the name used by most people to call a publicly available online site such as Microsoft.com or YouTube.com and so on. A website is a collection of one or more web pages and several other resources such as images, videos, scripts, etc. Although a website is typically made of many web pages, recent technologies such as HTML5 and CSS3 allowed rich websites to be constructed based on a single HTML file (webpage). Regardless of how many web pages make up the site, its resources are hyperlinked and are organized in one single cyberspace location. A picture on this webpage may be from a totally different online location and yet for the user, it feels like it's part of the page. The concept of the hyperlink is one of the most powerful and effective features of the Web. With a single click you are taken from a webpage hosted in Dubai, UAE, to another page hosted in Florida, USA.
Public vs. Private
Most website are available publically which means anyone with an Internet connection can access them using a web browser. Sometimes the website is available only internally for selected users such as the employees of an organization. We call such websites, Intranet sites. An Extranet site, on the other hand, is a website that is also open for a selected category of "external" users such as the partners or suppliers of an organization for example. Intranets are often hosted within the local network (but may also exist publically). Extranets can be publically available but with restricted access (login credentials are required).
When a website, internal or public, presents a gateway into many related resources, content, and services, such as student services for example, the website is referred to as a Portal. A college portal is a good example.
Static vs. Dynamic
Whether a website is public or private (internal), it may be classified as static or dynamic based on the content it provides. If the content of the website is fixed and hard-coded into web pages, we call it static. Such websites offer no valuable functionality. This is your typical informational website for small companies (about us, contact us, our products, etc.). On the other hand, if the content of the website is data-driven (or dynamic), the website often provides functional services. Let’s say you’re a student and you logged in to your college portal. What will you see? You will see your profile page, your own schedule and courses, your grades and GPA, and so on. Another student accessing the same page will see her or his profile. Therefore, this profile page (although it’s the same), its content (data) is dynamic and is based on who logs in.
Static websites offer nothing exciting for attackers to target. Web applications, or dynamic websites, on the other hand, often involve private and confidential data that become the target of attacks.
Web 1.0
AKA the Static Web, Web 1.0 was the first public iteration of the web which was mainly static and was served directly from the server's file system.
Web 2.0
AKA the Social Web, Web 2.0 is focuses on user-generated content and content that is dynamic responsive to user input. Examples of Web 2.0 sites include Facebook, Twitter, Wikipedia, Instagram, and so on.
Web 3.0
AKA the Decentralized Web, Web 3.0 is the latest evolution of the web, and is based on Blockchain technology. Web 3.0 offers data ownership, transparency, and freedom through decentralization. Technically, Web 3.0 provides APIs that allow us to work with the blockchain. Web3 uses JSON RPC*.
References
Ads by GoogleWeb Application ArchitectureSo what are the components that make up a web application and how are they related? In its simplest form, a web application involves two components:
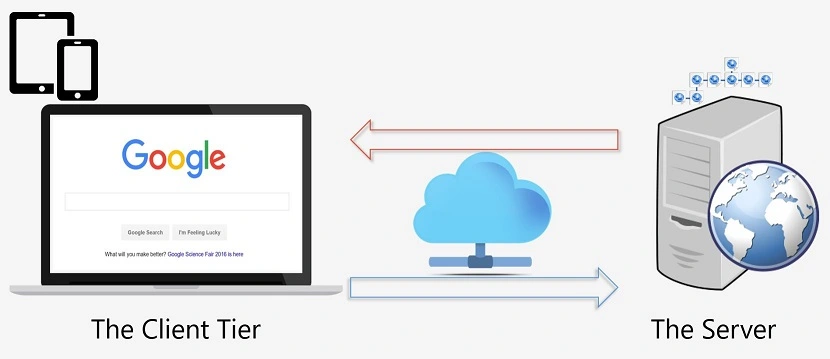
Figure 1.1: Client Server HTTP Model
Architecture TiersClient Tier
The client is the web browser on the user's personal computer. The client is the component that initiates the communication in this Request-Response model. This is a person (the user) opening her favorite web browser and accessing a website. The client "component" in this architecture is called the Client Tier.
Middle Tier
The server is a computer with a special software called HTTP server, or more commonly, web server. The web server listens to incoming requests and responds back via HTTP (or HTTPS but more on this later). The web server belongs to the second tier in this client-server model; AKA the Middle Tier.
The middle tier may include a more advanced server responsible for complex business logic, known as the Application Server (such as WebSphere or JBoss for example). When the application server is present, the web server is responsible only for "presentation" (i.e. presenting the web pages).
Data Tier
As mentioned earlier, meaningful and functional websites, involve dynamically rendered data often residing in a database. The database may reside on a dedicated server, and belongs to a layer known as the Data Tier. Examples of databases include MySQL, SQL Server, and Oracle.
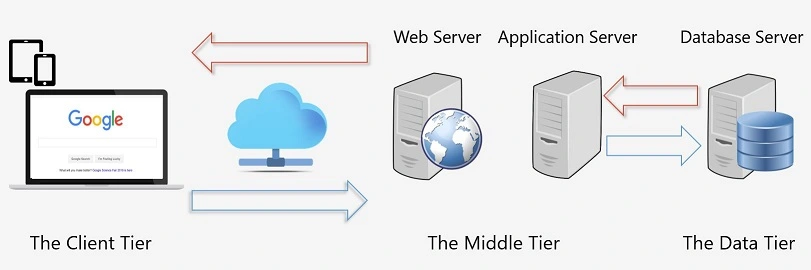
Figure 1.2: Web Architecture
HTTP
"The Hypertext Transfer Protocol (HTTP) is a stateless application-level protocol for distributed, collaborative, hypertext information systems" [2].
HTTP is the Hypertext Transfer Protocol: A client contacts the server requesting a webpage and the server responds. Both the client and the server are software programs or applications. The client is the web browser. The server such as Apache or IIS, for example, are also software applications that you can download and install on any computer. The way these two programs communicate is through a protocol called HTTP. HTTP operates on the application layer of the OSI model.
HTTP, the "Web Protocol" is based on a simple Request-Response paradigm. The default port of HTTP is 80 (i.e. port 80 is open on the web server in order to allow web traffic). For secure communication between the client and the server, a secure version of HTTP is used (HTTPS). The default port of HTTPS is 443. When HTTPS is used, the data in transit between the client and the server is encrypted protecting it from eavesdropping.
HTTP Request
If we look at the header of an HTTP request, we would see the resource being requested and, among other things, a method of request. There are several request methods defined by RFC 9110 HTTP/1.1 [3]:
| Method Name | Description |
|---|---|
| GET | Transfer a current representation of the target resource. |
| HEAD | Same as GET, but do not transfer the response content. |
| POST | Perform resource-specific processing on the request content. |
| PUT | Replace all current representations of the target resource with the request content. |
| DELETE | Remove all current representations of the target resource. |
| CONNECT | Establish a tunnel to the server identified by the target resource. |
| OPTIONS | Describe the communication options for the target resource. |
| TRACE | Perform a message loop-back test along the path to the target resource. |
According to the RFC, all general-purpose servers must support GET and HEAD. However, the most relevant methods within the context of this book, are the GET and POST methods. The GET method is perhaps the most common request method. It is the method typically used when you enter an address of a website in your browser or when you click a link on a webpage. It is the method that "gets" a web resource.
The POST method, on the other hand, is the method that sends data to the server. It is the typical method of choice when you submit an online form. The data in the form is sent in the body of the HTTP request.

Figure 1.3: HTTP Request Header
Figure 1.3 above shows a sample HTTP Request header (captured in a tool like Burp Suite for instance). The header shown has a GET method. The Accept field is used to specify media types which are acceptable for the response (e.g. images/jpg or text/html). The Referer (no it's not a book typo, it's an HTTP specs typo that never got corrected) field identifies the URI that linked to the requested resource. The User-Agent is simply the browser acting as an agent on the our behalf, the user. Host is the domain name of the server. The Connection field allows the sender to indicate control options for the current connection. So "close" means connection must be closed after the resources is received.
HTTP Response
The header of the response reveals data such as the server name, date and time, but also the actual resource being requested. What is relevant to this course is a response code that represents the status. There are several codes and I am almost sure you have seen some client error codes such as the infamous 404 page not found error. Without exploring the header, there is no reason for a user to see codes other than error codes. In fact, a good website would respond with a user friendly error page sparing the surfer from seeing the error code.
"The status code of a response is a three-digit integer code that describes the result of the request and the semantics of the response, including whether the request was successful and what content is enclosed (if any). All valid status codes are within the range of 100 to 599, inclusive." [3]
Here are the response Status Codes categories as defined by RFC 9110 HTTP/1.1:

Figure 1.4: HTTP Response Header
URL Components
Consider this URL (Uniform Resource Locator):
http://www.sameraoudi.com:80
/courses/page.php?number=2&lang=eng
http This is the protocol and may be HTTP or HTTPS (for web traffic)
www The host (somtimes a subdomain such as courses.sameraoudi.com)
sameraoudi.com The domain name you purchase (rent really)
:80 The port (if it's the default port such 80 for HTTP or 443 for HTTPS, then no need to explicitly include it
/courses/page.php The resource (document) path
? The start of a query
number=2 A query (or URL) parameter and its value
&lang=eng Another query parameter and its value
References
Client-Side vs. Server-Side TechnologiesSince attackers exploit vulnerabilities in technologies, it is important to examine the tools and technologies that exist on both sides, the client and the server.
Client-SideClient side technology is the stuff we can see and access on our computer. Like what? The web browser obviously but also the webpage we request from the server is sent to us to browse. Here is a list of some relevant client-side technologies:
The Web Browser
The Web Browser (IE, FireFox, Chrome, etc.) is the client that directly communicates with the server via HTTP. The job of the browser is to render HTML code into visual web pages. It read the HTML markup (along with any styling and scripts) and translates it into what people see on the webpage. Although web browsers are mainly doing the same things, some browsers interpret the underlying code differently causing inconsistent display across the browsers. Recentl however, all browsers have been moving toward compliance with standards.
The Webpage
The Webpage (HTML) is the document that gets displayed in the web browser. The webpage has two sides: 1) the visual presentation people see directly in the browser, and 2) the underlying HTML code that can be seen by viewing the source of the page (right-click and view source)
JavaScript
JavaScript is the main client-side scripting language of the Web. JavaScript gets interpreted by the web browser. JavaScript has many uses among which is the ability to control the webpage document and the browser it resides within. Because of its nature and the fact that it gets sent to us (the client), JavaScript can be a security threat.
Cascading Style Sheets (CSS)
CSS is the styling, or formatting language of web pages. Using CSS, one can define HOW the webpage should be displayed. Because of its role, CSS generally poses no security threat.
Let's discuss an example. You open your favorite Web Browser and type in an address of a website. When you hit enter, your browser initiates an HTTP Request using the address (or URL) you provided. It will first resolve this human-friendly address into the IP address of the server usinf the Domain Name System (DNS). Once the address is resolved and the server is found, HTTP communication is established. The server is a machine that listens for incoming HTTP Requests, and responds accordingly. The server sends back the requested resource (webpage) in an HTTP Response. The webpage may be written in a number of languages but what gets sent to the client is HTML code and associated resources (e.g. JavaScript, CSS, images, etc.). The client (web browser) receives the HTML code and translates it into the webpage we see. The translation process includes: 1) displaying WHAT is supposed to be displayed as defined in the HTML code, and 2) HOW it should be displayed as defined by CSS.
As mentioned above, along with the webpage the server sends other related artifacts such as JavaScript. JavaScript is scripting language that operates within the web browser and has the ability to manipulate it (change size, close window, redirect webpage, alert the user, etc.).
HTML Overview
HTML, or Hypertext Markup Language, is a very simple "presentation" language. The language consists of a predefined set of tags (or elements) that provide "instructions" to the web browser on what to display. The markup is the tag defined by the <> special characters.
The HTML syntax is very simple. It involves three components only:

Figure 1.5: Non-Empty Element
In figure 1.5 above, the a (anchor) element is broken down into its different components to demonstrate the anatomy of HTML code. The element (or tag) name is a. It has one atrribute (it can have more) called href which has a value. The anchor element defines a hyperlink. Its href attribute specifies where the link points to. And finally, the content of this element is the link text (or label) that people click. The a is a non-empty element and is therefore closed in a separate closing tag.
In the empty element img shown in figure 1.6 below, the tag is closed at the end with the forward slash without the need for a closing tag. Like the name suggests, empty elements have no content. In this case the img element tells the browser to place an image on the webpage. The source of the image is specified in the value of the src attribute. The alt attribute defines an alternative text to be displayed in case the image is not rendered on the browser (as in text-only browsers for example). Also, in such cases a text-to-speech reader would provide an audio for the visually impaired.
Figure 1.6: Empty Element
Creating web pages is very easy. In fact, HTML may be the easiest programming language to learn. It doesn't really support the ususal programming logic and constructs such as loops. In addition, you don't special programs to create or run your code. A simple text editor such as NotePad can get you started, and any web browser can be used to view the rendered output (the webpage). Examine the code of a simple webpage that has minimum content. The webpage starts with a doctype definition telling the browser what type of document this is (you may exclude this but it doesn't hurt to get used to doing things properly).
Next is the start of the HTML document defined by the root [parent] element, the html tag. The html element has two children, head and body. The head element defines header information and properties of the document (such as the title, metadata, stylesheets, etc.). The actual webpage we see in our web browsers, is the content enclosed within the body element.
<!doctype html>
<html>
<head>
<title> First HTML Webpage <title>
</head>
<body>
Hello HTML World!
<img src="myphoto.jpg" />
</body>
</html>
Code 1.1: Simple WebpageServer-Side
As the name suggests, server-side technology resides and runs on the server. But what does that really mean? It simply means that we cannot see or access this technology. Instead, we see the resulting output that gets produced by this technology (typically in the form of the HTML webpage).
Here is a list of server-side technologies that are relevant to this book:
The Web Server
The Web Server or the HTTP server is a dedicated program that runs on the server machine. Listening on default port 80 (or 443 for HTTPS), the web server expects, and is therefore open for, HTTP traffic. When an HTTP Request is received, the server decides how to respond based on the availability of the resource and the authorization level of the client (among other things). There are several web server software out there, but the most popular are Apache, Microsoft IIS, NGINX, and Google Web Server. According to a 2022 study by NetCraft, Apache is the number one server in terms of market share for active sites [4].
Server-Side Programming
Server-Side Programming Languages provide the mechanism to develop the functional business logic of the web application. These languages along with their runtime environments and entire platforms exist in the middle tier. Examples of server-side languages include: PHP, JSP, ASP, Python, Ruby, and so on.
Databases
Database Management Systems (DBMS) exist in the data tier all the way at the backend of the web application, and provide the tools and mechanisms for creating, managing, and accessing databases. Examples of DBMS include: MySQL, SQL Server, DB2, Oracle, and so on.
References
Chapter 1 SummaryChapter 1 Revision QuestionsAds by Google