Module 6: Incident Response and Disaster RecoveryIntroduction to Information Security Samer Aoudi
Learning OutcomesAn overview of IR and DR
While organizations would prefer to prevent security breaches and incidents, they must expect the unexpected and plan for the worst. In module 1, we introduced the five core functions of the NIST Cybersecurity Framework (CSF):
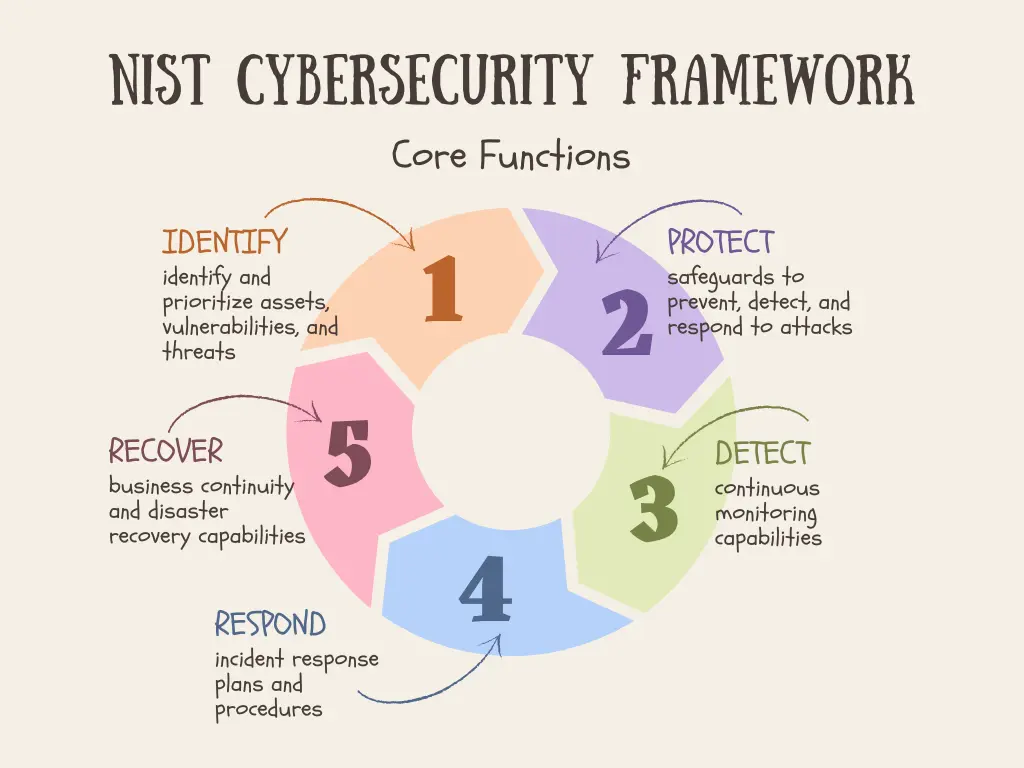
Figure 6.1: NIST CSF Core Functions
The reality is there are no foolproof safeguards and incidents may occur. We must be prepared when the "protect" function fails, and this entails the ability to detect an incident and then respond to it. In other words, we need planning.
Planning is an essential aspect of information security. It is the process of identifying potential security risks and developing strategies to mitigate or avoid them. Without proper planning, organizations are vulnerable to security incidents that can cause significant damage to their operations and reputation. A comprehensive security plan helps an organization to identify its critical assets, assess its vulnerabilities, and develop a response plan in case of an incident. It also helps an organization to comply with industry regulations and standards, and demonstrate due diligence to stakeholders. By taking a proactive approach to information security, organizations can reduce the likelihood of security incidents occurring and minimize the impact if they do occur.
Definitions
Before we dig deeper into IR and DR, let us discuss few important concepts:
Incidents
In the context of information security, an incident refers to any event that poses a threat to an organization's information systems, network, or data. This can include a wide range of events, such as cyber attacks, data breaches, system failures, and natural disasters. Some examples of security incidents include:
Contingency planning
Contingency planning, also known as business continuity planning, is the process of identifying potential risks and disruptions that may affect an organization's operations, and developing strategies to mitigate or avoid them. In the context of information security, contingency planning is the process of preparing for and responding to security incidents and disasters that may impact an organization's information systems, network, or data.
The goal of contingency planning is to ensure that an organization can continue to operate in the event of a security incident or disaster. It involves identifying critical systems and data, assessing vulnerabilities, and developing procedures for restoring operations as quickly as possible. This includes identifying alternative facilities, equipment, and personnel that can be used in case of an incident, and testing and maintaining the readiness of the organization to respond to an incident.
It is important to note that contingency planning is a continuous process that requires regular review, testing, and updating to ensure that it remains effective in the face of changing threats and vulnerabilities.
Incident response (IR)
Incident response refers to the processes and procedures that an organization follows when a security incident occurs. It is the process of identifying, containing, assessing, and resolving security incidents. The goal of incident response is to minimize the impact of an incident and return the organization to normal operations as quickly as possible.
Incident response includes several key phases [1]:
Disaster recovery (DR)
Disaster recovery (DR) is the process of restoring critical systems, networks, and data after a disaster occurs. The goal of disaster recovery is to minimize the impact of a disaster on an organization's operations and ensure that essential systems and data are available as quickly as possible.
Disaster recovery includes several key elements [2]:
Business Continuity (BC)
Business continuity refers to the ability of an organization to maintain its operations and critical functions during and after a disruptive event. The goal of business continuity is to minimize the impact of a disruptive event on an organization's operations, and to ensure that essential systems, applications, and data are available as quickly as possible.
The need for IR and DR
Incident response and disaster recovery are critical components of an overall information security strategy. They are designed to minimize the impact of security incidents and disasters on an organization's operations and to ensure that essential systems, applications, and data are available as quickly as possible.
The importance of incident response lies in its ability to quickly identify, contain, and resolve security incidents. This minimizes the impact of the incident and helps to prevent it from spreading. Additionally, incident response helps organizations to quickly restore normal operations and protect their reputation by controlling the spread of information about the incident.
Disaster recovery is equally important as it provides an organization with the capability to restore critical systems, applications, and data in the event of a disaster. This enables an organization to continue its operations and minimize the impact of the disaster on its customers, partners, and stakeholders.
Both incident response and disaster recovery are also important for compliance reasons as many regulations and standards, such as the General Data Protection Regulation (GDPR) and the Payment Card Industry Data Security Standard (PCI DSS) require organizations to have incident response and disaster recovery plans in place.
Goals of IR and DR
The goals of incident response and disaster recovery are closely related and are designed to minimize the impact of security incidents and disasters on an organization's operations [2].
The main goals of incident response are:
The main goals of disaster recovery are:
While we prefer to prevent security breaches and incidents, we must expect the unexpected and plan for the worst. This include IR and DR plans and procedures allowing us to respond to and recover from incidents.
References
Incident Response
Incident response refers to the process of identifying, containing, eliminating, and recovering from security incidents.
Stages of incident response1 - Preparation
The preparation phase involves establishing the policies, procedures, and teams necessary to effectively respond to security incidents. This includes developing incident response policies, procedures, and teams, as well as defining communication and reporting protocols and providing incident response training.
The preparation phase is critical to ensuring an effective incident response. Without proper preparation, an organization may be unable to respond to security incidents in an organized and effective manner, leading to increased damage and disruption. By establishing clear policies, procedures, and teams, and providing incident response training, organizations can increase their readiness to respond to incidents, minimize the damage and disruption caused by incidents, and recover from incidents more quickly.
The preparation stage includes:
Incident Response Policies
During the preparation stage, we must Develop policies that outline the organization's approach to incident response, including the types of incidents that will trigger an incident response, who is responsible for responding to incidents, and the roles and responsibilities of incident response team members.
IR policies in an organization are typically developed by a combination of stakeholders, including senior leadership, information security, legal, and human resources departments.
Incident response procedures
We must also establish clear procedures for responding to incidents that ensure effective, efficient, and consistent responses.
Incident response teams
Organizations must select individuals or teams responsible for responding to incidents and assigning clear roles and responsibilities.
Incident response teams are groups of individuals within an organization who are responsible for responding to security incidents. The exact composition of an incident response team will depend on the size and structure of the organization and the types of incidents they may encounter.
In general, incident response teams should include individuals with a range of technical and business skills, including information security, network administration, system administration, database administration, legal, and human resources. The goal is to ensure that the incident response team has the necessary knowledge and skills to respond to incidents effectively and efficiently.
Communication and reporting protocols
Another important aspect of the prepration stage is to outline the process by which incidents are communicated and reported within an organization. This includes defining who will be notified of an incident, how incidents will be communicated and reported, and what types of information will need to be collected and reported.
Effective communication and reporting protocols are critical to ensuring an effective incident response. They help to ensure that incidents are communicated and reported quickly and accurately, and that the incident response team has the information they need to respond to incidents effectively.
When defining communication and reporting protocols, organizations should consider the following:
Testing incident response plans
Testing refers to the process of validating and testing the policies, procedures, and teams established in the preparation phase. The goal of testing incident response plans is to ensure that they are effective and capable of responding to incidents.
Testing IR plans can take many forms, including scenario-based exercises, tabletop exercises, and simulated incidents. These exercises can help to identify any gaps or weaknesses in the incident response plans, and allow organizations to refine their policies, procedures, and teams as needed.
2 - Identification
The identification stage in IRrefers to the process of detecting and confirming the presence of an incident. This stage is critical because it sets the stage for the subsequent stages of incident response, and helps to ensure that the incident response team is able to respond to the incident effectively.
The goal of the identification stage is to quickly and accurately detect and confirm the presence of an incident, and to collect and preserve as much information about the incident as possible. To achieve this goal, organizations typically employ a combination of monitoring and detection technologies, such as intrusion detection systems, anti-virus and anti-malware tools, and log analysis tools.
When an incident is detected, it is important to quickly and accurately assess the scope and impact of the incident, and to determine if the incident is a true security breach. This assessment should be done in a systematic and repeatable manner, and should be based on a pre-defined set of criteria.
Once an incident has been confirmed, the incident response team should be notified, and a plan of action should be developed to contain, assess, and respond to the incident. It is important to document all actions taken during the identification stage, as this information will be used to inform the subsequent stages of incident response.
The following is an example of incident identification in a network security context:
3 - Containment
The containment stage in incident response refers to the process of isolating the affected systems and stopping the spread of the incident. This stage is critical because it helps to minimize the damage caused by the incident and to prevent the incident from spreading to other systems or networks.
The goal of the containment stage is to quickly and effectively contain the incident and prevent further damage. To achieve this goal, the incident response team may take a number of actions, such as disconnecting affected systems from the network, isolating the affected systems, or implementing other technical or procedural controls to stop the spread of the incident.
It is important to carefully consider the containment strategy, as the wrong containment strategy can actually make the situation worse. For example, disconnecting affected systems from the network may prevent the incident from spreading, but it may also result in data loss or other unintended consequences.
In addition to technical containment measures, the incident response team should also consider non-technical containment measures, such as communication and coordination with other stakeholders, such as law enforcement or regulatory agencies.
Continuing from the identification example above: Suppose an intrusion detection system (IDS) detected a high volume of incoming traffic from a single IP address and raised an alarm, which was verified by the security operations center (SOC) as a genuine security incident. The incident response team was notified and collected information about the incident. In the containment stage, the incident response team may take the following actions:
4 - Analysis (Assessment)
Once the incident has been contained, the incident response team can then move on to the next stage of incident response, which is assessment. The information gathered during the containment stage will be used to inform the assessment stage and to help the incident response team determine the best course of action to respond to the incident.
The analysis stage in incident response is the process of collecting and analyzing information about the incident to determine the cause and impact of the incident. The goal of this stage is to understand the full extent of the incident, including what systems and data were affected, what caused the incident, and what impact the incident has had on the organization.
The incident response team will use a variety of tools and techniques to gather information about the incident, including reviewing system and network logs, interviewing personnel, and conducting forensic examinations of affected systems.
The information gathered during the analysis stage will be used to determine the root cause of the incident, to determine the extent of the damage, and to develop a plan of action to respond to the incident. The incident response team may also need to coordinate with other stakeholders, such as law enforcement or regulatory agencies, to gather additional information about the incident.
5 - Eradication
The eradication stage in incident response is the process of resolving the incident and restoring the affected systems to their normal state. The goal of this stage is to remove the cause of the incident and to restore normal operations as quickly as possible.
The incident response team will use the information gathered during the analysis stage to determine the best course of action to resolve the incident. This may include steps such as cleaning up infected systems, patching vulnerabilities, and restoring data from backups.
In some cases, it may also be necessary to implement additional security measures to prevent similar incidents from occurring in the future. This could include deploying new security technologies, updating security policies, or retraining personnel on security best practices.
It is important to thoroughly eradicate the incident to ensure that the cause of the incident is fully removed and that the systems are restored to their normal state. A well-executed eradication stage can help to minimize the impact of the incident and to prevent similar incidents from occurring in the future.
Example: The incident response team, after conducting a thorough analysis of the incident, discovered that the email account was compromised by a phishing attack. The attacker was able to gain access to the email account by tricking the employee into entering their login credentials on a fake login page. During the eradication stage, the incident response team took the following actions to resolve the incident:
6 - Recovery
The recovery stage in incident response is the process of resuming normal operations and returning the organization to business as usual. This stage begins once the incident has been resolved and the affected systems have been restored to their normal state.
During the recovery stage, the IR team will need to assess the impact of the incident and determine the steps necessary to resume normal operations. This may include tasks such as restoring systems and data, reestablishing communication and data networks, and testing systems to ensure they are functioning properly.
In some cases, it may also be necessary to make changes to the organization's security posture in response to the incident. For example, if the incident was caused by a vulnerability that was exploited, the organization may need to implement additional security measures to prevent similar incidents from occurring in the future.
It is important to thoroughly recover from the incident to ensure that the organization is able to return to business as usual as quickly as possible. A well-executed recovery stage can help to minimize the impact of the incident and to prevent similar incidents from occurring in the future.
Continuing with the example from the "Eradication" stage, where an employee's email account was compromised. In the recovery stage, the IR team took the following actions:
By thoroughly recovering from the incident, the incident response team was able to minimize the impact of the incident, restore normal operations, and prevent similar incidents from occurring in the future. This demonstrates the importance of having a well-planned and well-executed incident response plan in place to effectively respond to security incidents.
7 - Post-Incident Activity
The post-incident activity stage in incident response is the process of reviewing the incident and evaluating the effectiveness of the incident response plan. This stage is critical for ensuring that the organization is better prepared to respond to future incidents and that any areas for improvement in the incident response plan are identified and addressed.
During the post-incident activity stage, the incident response team will need to review the incident and the actions taken during the incident response process. This may involve tasks such as conducting a root cause analysis, reviewing the documentation of the incident, and interviewing team members involved in the response effort.
Based on the results of the review, the incident response team will then evaluate the effectiveness of the incident response plan and identify areas for improvement. This may include updating the incident response plan, providing additional training to team members, and improving the organization's security posture.
Example - After a phishing attack was successfully contained and eradicated, the incident response team conducted a post-incident activity review. This involved the following actions:
IR is a process of responding to an unplanned event or a security breach that has the potential to cause harm to an organization. It involves identifying, containing, analyzing, eradicating and recovering from the incident. Effective incident response is crucial to minimize damage and ensure a rapid return to normal operations.
References
Disaster Recovery
Disaster recovery refers to the process of restoring systems, data, and operations to a normal state after a disaster or major disruption has occurred. A disaster can be defined as any event that severely disrupts normal business operations and threatens the availability of critical systems and data. Disaster recovery is a critical component of an organization's overall business continuity plan and is designed to minimize the impact of a disaster on business operations. The goal of disaster recovery is to ensure that critical systems and data are restored as quickly as possible and that business operations can resume as normal. This is achieved through the creation of a comprehensive disaster recovery plan that outlines the procedures and processes for responding to disasters and restoring critical systems and data.
| Type of Disaster | Definition | Example |
|---|---|---|
| Cyber Attacks | Disasters caused by unauthorized access or damage to an organization's computer systems and networks by a malicious attacker | A hacker gains access to a company's network and steals sensitive customer data, such as credit card numbers and addresses |
| Data Breaches | Disasters caused by unauthorized access to or theft of sensitive information stored in digital form | An unauthorized individual gains access to an organization's database and copies or exfiltrates confidential information, such as employee records or financial data |
| System Failures | Disasters caused by unplanned interruption of computer systems and networks due to technical issues or component failures | A power outage or hardware malfunction causes a company's servers to shut down, resulting in data loss or the inability to access critical systems |
| Human Errors | Disasters caused by mistakes made by employees or contractors that result in data loss or system failure, such as accidental deletion or incorrect configuration | An employee accidentally deletes critical files or configurations, causing system failure or data loss |
| Natural Disasters | Disasters caused by events like hurricanes, earthquakes, and floods that can disrupt an organization's IT infrastructure and result in data loss or system failure | A hurricane damages an organization's data center, causing hardware failure and data loss |
Table 6.1: Types of Disasters
disaster recovery planning
Disaster recovery planning is the process of creating a comprehensive plan for how an organization will respond to and recover from a potential disaster. The goal of disaster recovery planning is to minimize the impact of a disaster on an organization's operations and to ensure that critical systems and data can be restored as quickly as possible.
A well-designed disaster recovery plan should include the following components:
Risk Management
This element of disaster recovery involves identifying and evaluating potential threats to an organization's IT infrastructure and data, and implementing measures to minimize or mitigate these risks. This may include conducting regular security assessments, implementing disaster recovery plans, and performing regular backups.
Business Impact Analysis (BIA)
BIA is a process of evaluating the potential impact of a disaster on an organization's operations, including the impact on revenue, customers, employees, and other stakeholders. This information is used to prioritize the critical systems and data that must be protected in the event of a disaster.
Backup and recovery strategies
Backup and recovery strategies are key components of a disaster recovery plan. These strategies should include regularly scheduled backups of critical systems and data, as well as plans for how to restore data and systems in the event of a disaster. The backup and recovery strategies should also include considerations for data protection and security, such as data encryption and secure storage of backup copies.
Alternate site
An alternate site is a location where critical systems and data can be relocated in the event of a disaster. This can include an off-site data center, a cloud-based solution, or a secondary physical location. The alternate site should be equipped with the necessary hardware and software to support the organization's operations in the event of a disaster.
Testing
Regular testing of disaster recovery plans and procedures is essential to ensure that the plans are effective and that all stakeholders are prepared to respond in the event of a disaster. This may include regular simulated disaster scenarios, as well as regular testing of backup and recovery procedures.
Maintenance
Regular maintenance and updating of disaster recovery plans and procedures is essential to ensure that the plans remain effective and up-to-date. This may include updating backup and recovery procedures, reviewing and revising risk management strategies, and performing regular security assessments. Regular training for all stakeholders involved in disaster recovery is also important to ensure that everyone is prepared to respond effectively in the event of a disaster.
Disaster recovery execution
Disaster recovery execution refers to the actual implementation of the disaster recovery plan in response to a disaster. This stage of disaster recovery is crucial as it determines the success of the overall disaster recovery effort. Among other steps, recovery execution includes the following steps:
Alternate sites
Alternate sites are backup facilities or locations that can be used as a replacement for a primary site in the event of a disaster. They are used to support the continuation of critical business operations during and after a disaster. The following are some of the common types of alternate sites (description is provided in the table below):
| Type of Site | Description |
|---|---|
| Hot site | A fully functional and equipped backup facility that is ready to be used immediately in the event of a disaster, with redundant systems and data storage, as well as network and communications infrastructure. |
| Warm site | A backup facility with a lower level of infrastructure and equipment, requiring some setup and configuration time before it can be used in the event of a disaster. |
| Cold site | A basic backup facility with minimal infrastructure and equipment, requiring a significant amount of time and resources to be brought up to operational status in the event of a disaster. |
| Mobile site | A temporary facility that can be deployed quickly and easily in the event of a disaster, such as mobile trailers, RVs, or tents, and is often used for short-term disaster recovery scenarios. |
| Cloud-based site | A virtual backup facility hosted in the cloud, providing a flexible and scalable disaster recovery option that can be accessed from anywhere with an internet connection. |
Table 6.2: Types of Alternate Sites
DR is a critical aspect of overall business continuity planning and involves the processes and procedures to restore normal business operations after a disaster or disruption.
References
Incident Response case studyRansomware Attack at CSA CorporationProblem
CSA Corporation, a large financial services company, experienced a ransomware attack that encrypted critical data on its servers, rendering it inaccessible. The attackers demanded a large sum of money in exchange for the decryption key.
Solution
CSA Corporation immediately activated its incident response plan and formed an incident response team to contain and analyze the attack. The team performed the following steps:
Results
CSA Corporation was able to successfully recover its data and systems and prevent the attack from spreading further. The incident response team was able to contain and eradicate the attack in a timely manner, minimizing the impact on the business.
Case Study Questions
Attempt to answer the following questions before revealing the model answers:
This case study demonstrates the importance of having an incident response plan and a dedicated incident response team in place. The case study showcases the steps involved in incident response and highlights the importance of timely identification, containment, analysis, eradication, recovery, and post-incident activities.
Research AssignmentInvestigating the Importance of Incident Response and Disaster Recovery Planning: A Case Study AnalysisIntroduction
Incident response and disaster recovery are critical components of a comprehensive information security program. The ability to quickly and effectively respond to and recover from incidents can mean the difference between minor inconvenience and major business disruption. In this research assignment, students will explore the concepts, processes, and best practices of incident response and disaster recovery.
Instructions
Deliverables
Suggested Sources
Assessment Criteria
The assignment provides an opportunity for students to gain a deeper understanding of Incident Response and Disaster Recovery. The assignment focuses on the practical aspects of incident response and disaster recovery, enabling students to apply the theories and concepts they have learned in class to real-world scenarios.
Ads By Google
Module SummaryModule Revision QuestionsModule Glossary| Term | Definition |
|---|---|
| Incident | Any event that poses a threat to an organization's information systems, network, or data |
| IR | Incident response refers to the processes and procedures that an organization follows when a security incident occurs |
| DR | Disaster recovery is the process of restoring critical systems, networks, and data after a disaster occurs |
| Contingency Planning | is the process of identifying potential risks and disruptions that may affect an organization's operations, and developing strategies to mitigate or avoid them |
| BIA | Business Impact Analysis is a process of evaluating the potential impact of a disaster on an organization's operations, including the impact on revenue, customers, employees, and other stakeholders |
| Alternate Site | A location where critical systems and data can be relocated in the event of a disaster |